这节就是带大家去写一个多线程的爬虫,感受一下速度,废话不多说,上干货,强烈建议跟着我的步骤写一遍,这样印象更深刻
手写一个简单的爬虫的函数
这里用到了 requets 库和 bs4 库,这个没安装的可以安装一下,然后简单写个小 Fuc,目的是爬取一下酷狗音乐的 TOP500 的歌曲
import requests
import time
from bs4 import BeautifulSoup
urls = [
f'http://www.kugou.com/yy/rank/home/{page}-8888.html'
for page in range(1,24)
]
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
}
def crawler(url):
r = requests.get(url=url,headers=headers)
soup = BeautifulSoup(r.text, 'lxml')
ranks = soup.select('span.pc_temp_num') # 排行
titles = soup.select('div.pc_temp_songlist > ul > li > a') # 歌手名和歌曲名
times = soup.select('span.pc_temp_tips_r > span') # 歌曲时长
for rank, title, time in zip(ranks, titles, times):
data = {
'rank': rank.get_text().strip(),
'singer': title.get_text().split('-')[1],
'song': title.get_text().split('-')[0],
'time': time.get_text().strip()
}
print(data)
if __name__ == "__main__":
crawler(urls[0])
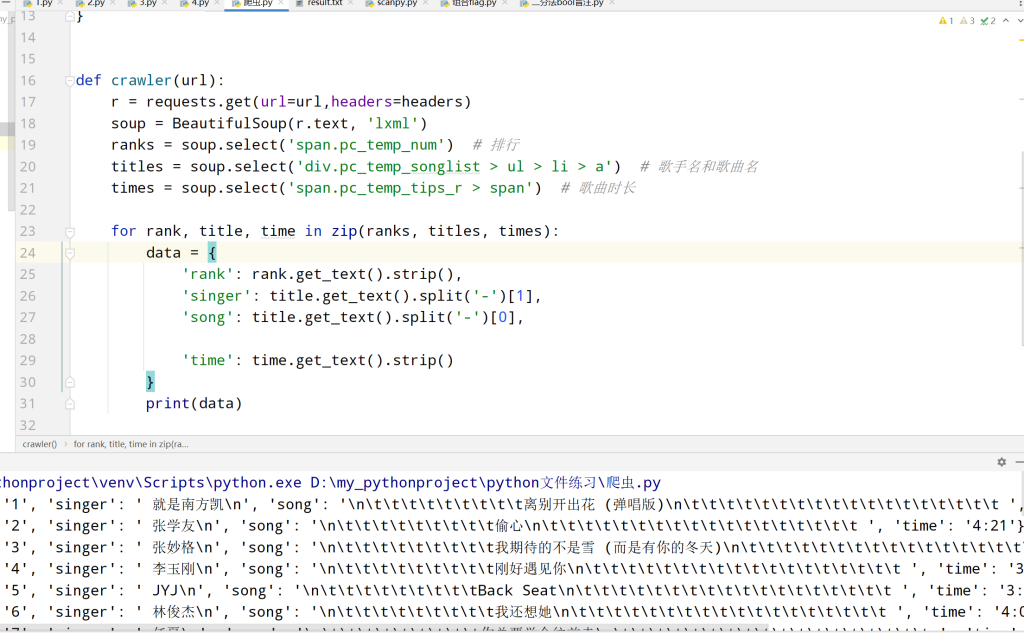
然后拿第一页测试一下,大概就是以下这个效果,\n\t 不知道从哪来的,好奇怪,不管了反正不是重点
然后可能有的同学不知道 if __name__ == “__main__“这个有啥用,我也给大家解释一下
一个python文件通常有两种使用方法,第一是作为脚本直接执行,第二是 import 到其他的 python 脚本中被调用(模块重用)执行。因此 if __name__ == 'main': 的作用就是控制这两种情况执行代码的过程,在 if __name__ == 'main': 下的代码只有在第一种情况下(即文件作为脚本直接执行)才会被执行,而 import 到其他脚本中是不会被执行的,这在我下面给的代码例子中也能很好的展现这一点
调用线程的两种方式
函数(这个是我个人比较喜欢用的)
在 Python3 中,Python 提供了一个内置模块 threading.Thread,可以很方便地让我们创建多线程。
threading.Thread() 一般接收两个参数:
-
线程函数名:要放置线程让其后台执行的函数,由我们自已定义,注意不要加
(); -
线程函数的参数:线程函数名所需的参数,以元组的形式传入。若不需要参数,可以不指定
然后这里写个小栗子
import time
from threading import Thread
def task():
print("开始做一个任务啦")
time.sleep(1) # 用time.sleep模拟任务耗时
print("这个任务结束啦")
if __name__ == '__main__':
print("这里是主线程")
# 创建线程对象
t1 = Thread(target=task)
# 启动
t1.start()
time.sleep(0.3)
print("主线程依然可以干别的事")
这里既然用到了这个 time 模块的话,就简单说一下吧,用到 time.sleep()的话其实就和调用 I/O 流的效果就是一样的,也就是说当前的线程会停止,然后切换线程
类
这里在上面的例子改编一下
import time
from threading import Thread
class NewThread(Thread):
def __init__(self):
Thread.__init__(self) # 必须步骤
def run(self): # 入口是名字为run的方法
print("开始做一个任务啦")
time.sleep(1) # 用time.sleep模拟任务耗时
print("这个任务结束啦")
if __name__ == '__main__':
print("这里是主线程")
# 创建线程对象
t1 = NewThread()
# 启动
t1.start()
time.sleep(0.3)
print("主线程依然可以干别的事")
这个主要的思想就是,新建了一个子类,继承了父类的方法,然后在 run 方法里面去写函数要实现的功能(至于为什么的话,还是看源码,里面有个 if 判断,如果没有继承的话,run 方法不会启动的),然后它的父类是内置类 Thread,必须要注意的一点就是,要重写父类的构造方法,因为看这个 Thread 的源代码里面的构造方法就会发现,它其实是会初始化很多属性的,如果没有的话,程序会报错
两种都说完了,我是比较喜欢第一种,所以接下来的演示,我都会选择第一种的写法
给酷狗爬虫加多线程
这里就模仿我第二板块给出的第一种示例就行,下面给出代码,这里的话目前就只能创建 url 数目的线程,也就是 23 个,要不然比如创建了 10 个线程,那么最终跑着跑着就会又变成了单线程,这个问题具体怎么解决,用到下节课讲的进程通信(生产者与消费者模式),这里先给出目前水平能写的代码
import craw
import threading
import time
def thread_crawler():
threads = []
for url in craw.urls:
threads.append(threading.Thread(target=craw.crawler,args=(url,)))
for thread in threads:
thread.start()
for thread in threads:
thread.join()
if __name__ == "__main__":
start = time.time()
thread_crawler()
end = time.time()
print('多线程花费时间',end-start)
下面是程序运行的效果图,可以看见还是非常快的,不到 3s 就爬取到了酷狗的 TOP 前 500,而且还有一个特点就是,会发现这个爬取出的结果是乱序的,这也很好理解,因为这个爬取是 CPU 去决定的,本身就是个随机的事情
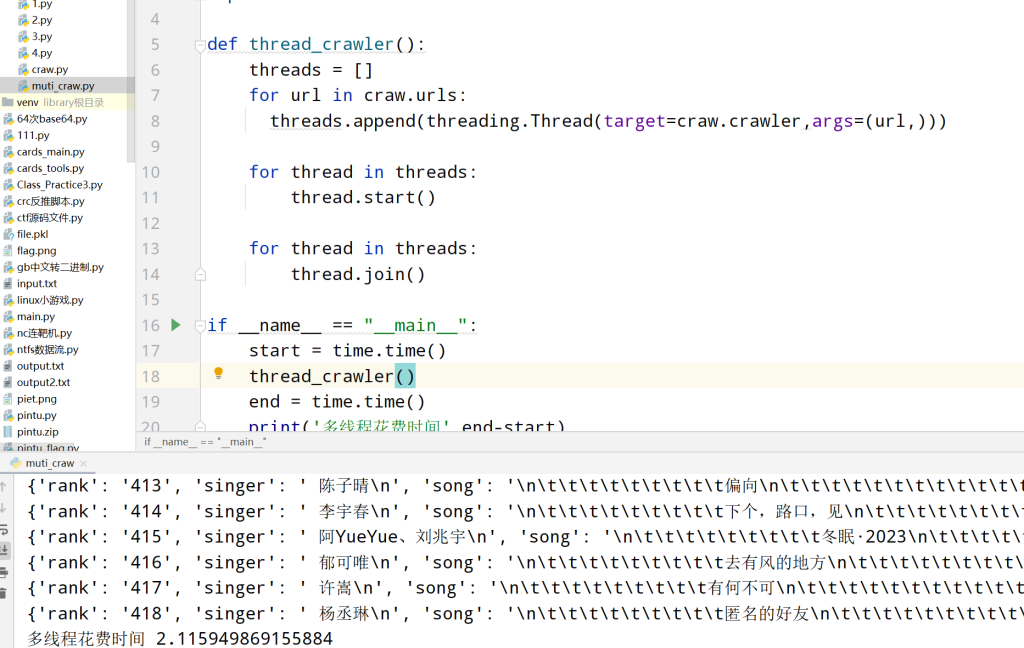
然后咱们来对比看一下,一开始写的单线程的爬取速度
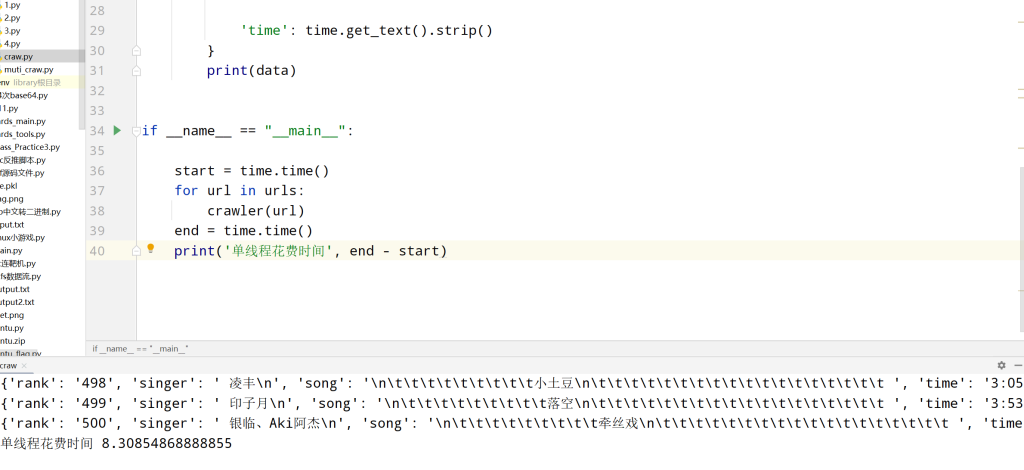
这个差距还是很明显的
OKK 这节就说到这里,大家能跟上敲一遍就敲一遍,下节继续讲怎么优化一下,不可能说有 1000 个网页,那我就要开 1000 个线程,有点太夸张了,写这样的代码肯定是不合理的