- 前言
这一个点网上没有人专门写出来哈,可能我纯是太闲,可能是我喜欢钻牛角尖,还是写一下这个点吧!
前情提示:这篇文章并不是说非要理解不可,在王爽的汇编语言里面也有说到“我们不必深究 assume 的作用,只要知道需要用它将你定义的具有一定用途的段和相关寄存器联系起来就可以了”,这篇文章就像是再给大家说明为什么“1+1=2”一样,所以这篇看不看无所谓啦

-
正文
1.我之前一开始也是认为只要伪指令中写了 assume cs:code,ds:data,ss:stack,那么就会有相关的寄存器和相应的段一一对应起来,但看到王爽对这个解释,才发现这个伪指令只是用来给编译器看的,只是让编译器去能翻译成更加合理的机器语言,所以得写上,而 CPU 处理我们定义的段中的内容,是当作指令执行,当作数据访问,还是当作栈空间,完全是靠程序中具体的汇编指令,具体要说的话就是下面的这两条指令(拿 data 举个例子)
mov ax,data
mov ds,ax
2.其实大家理解到这里就够了,以后用到什么段,就把与之对应的寄存器用 assume 这种伪指令连接起来就行了,反正多写一点伪指令肯定没有坏处,多写也能让编译器去更好的理解你所写的汇编语言,但真的只是这样吗?assume 是怎么去连接的?不是在后面会把段赋值给 ds 吗,那为什么还要去在首行去专门写一个 assume 呢?带着这些疑问,咱们接着往下看
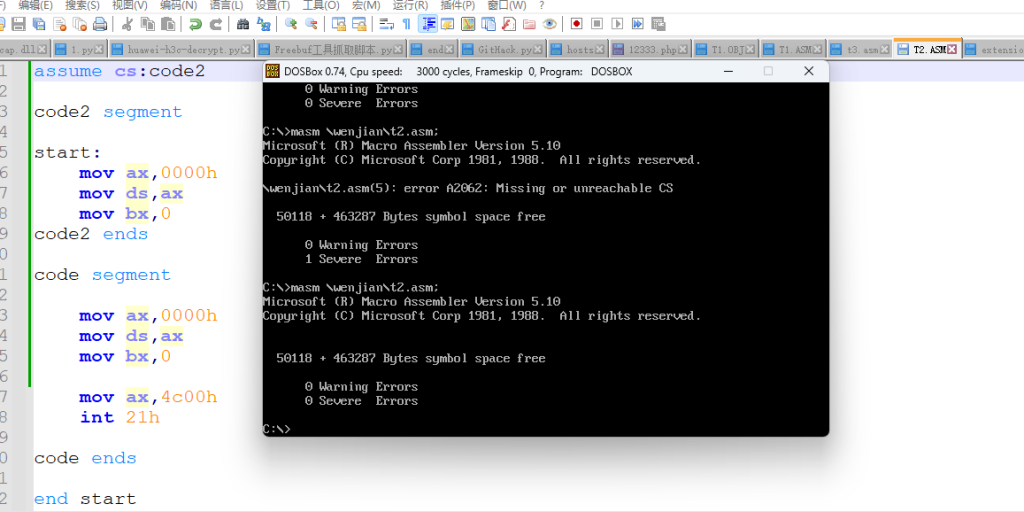
3.在一次调试代码的过程中,不写 assume 这个伪指令也可以正常的通过编译,这个情况就是我当时只写了一个代码段,并没有单独的将数据和代码分开,都是统一的写在代码段里面,这种情况下竟然是可以的,详情看下图
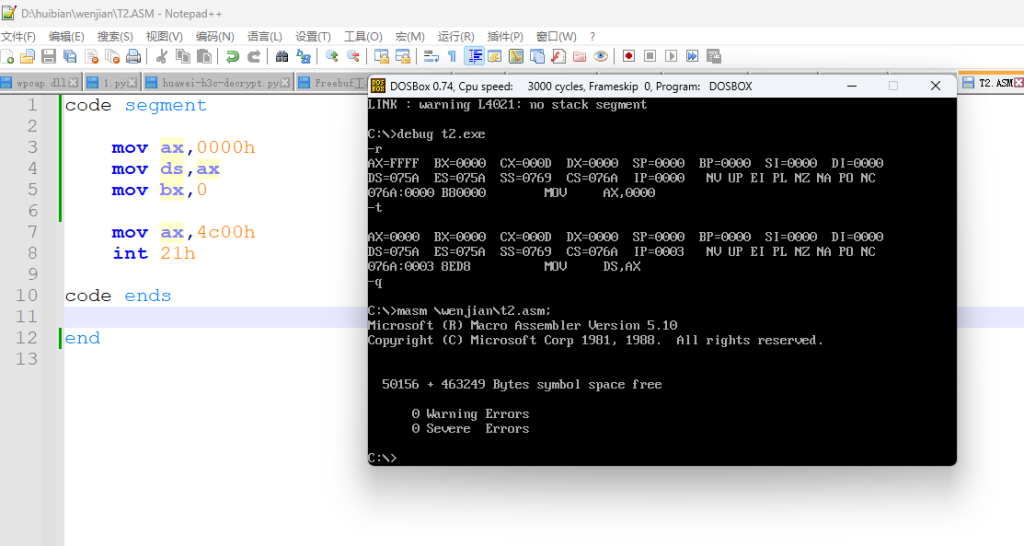
确实是没有报任何错误,然后就试了一下加入一个 start 看一下行不行,下面是验证的截图
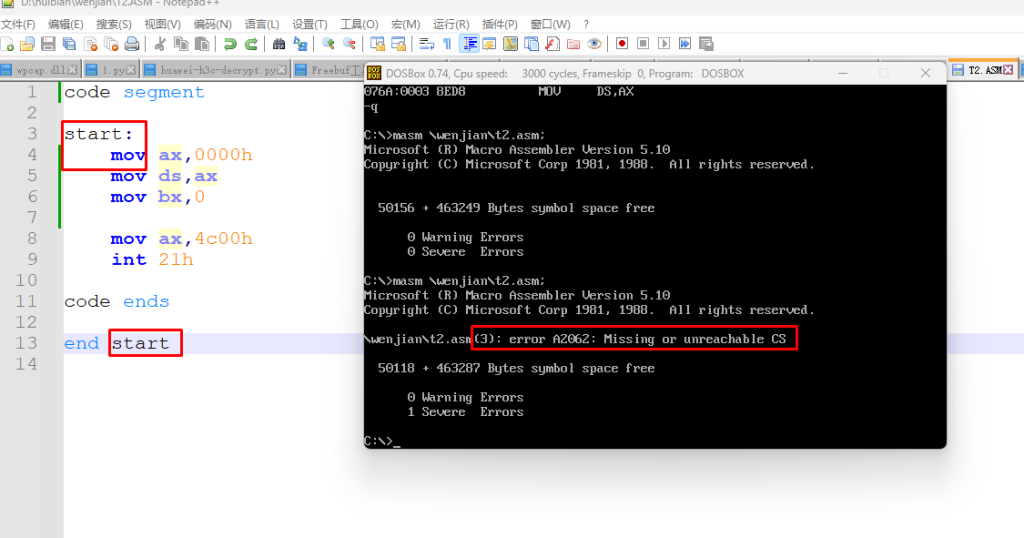
我们可以看到这个 masm 编译器报了一个错误:找不到 CS,这里大家就可以初步的看到这个 assume 的作用了,下面我加一个 assume 给大家看看效果,确实是没有再报错的
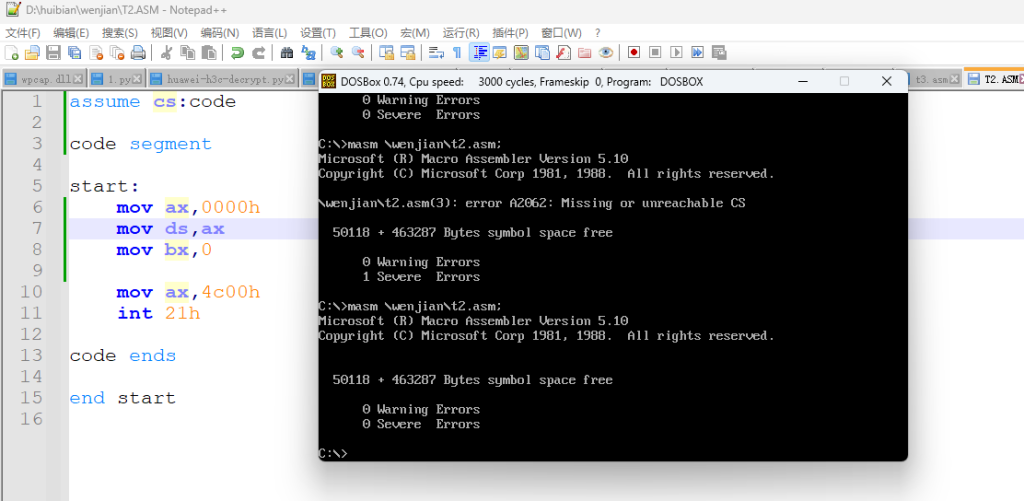
然后大家可能就会有疑问,为什么第一张图片啥也没写,反而可以呢?这个在王爽的一个实验中也是有所体现的,那个实验是去掉 start,问程序还能继续执行吗,而当时那个程序的第一个段正好是代码段,实验之后是可以执行的,也就是说,没有指明 end 后面的 start 那么编译器默认将 CS 指向首地址,也就是将 CS 等于这个段地址的值, 但如果一旦指明了 start 则必须写 assume,因为这个 start 是在 code 段里面,assume 得先告诉编译器 CS 与 code 关联起来,否则就会报错,再举个例子对比一下
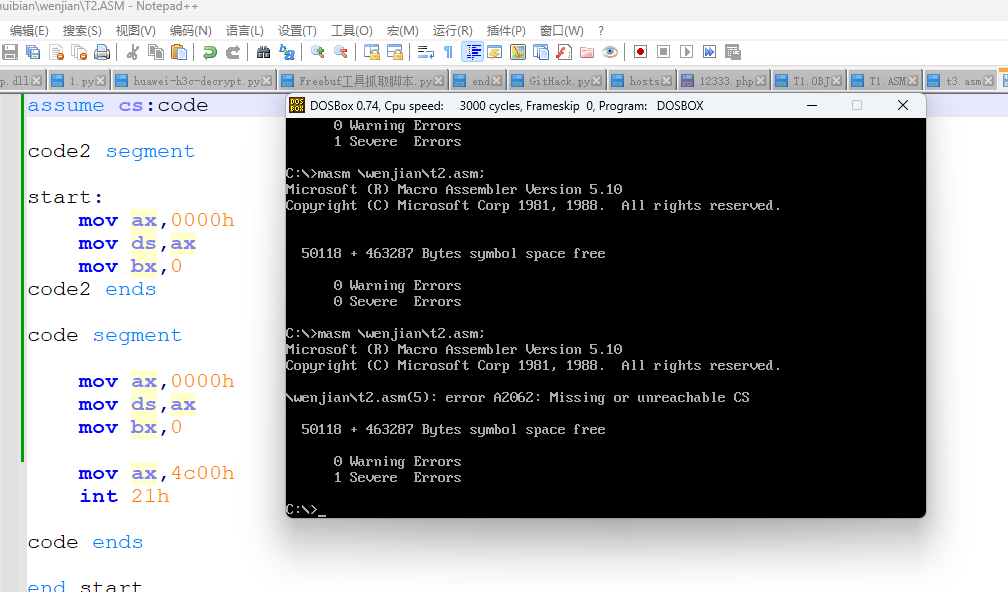
仔细对比两张图,相信大家就能明白这个 assume 与这个 end start 是密不可分的
通过上面的讲解给大家总结两句话
1.当一个段的时候,可以两个都不写(准确来说是将代码段写到第一个段就行)
2.当多个段的时候,要么把代码段放开头不用写start,要么就正常都写上,assume和end start是密不可分的
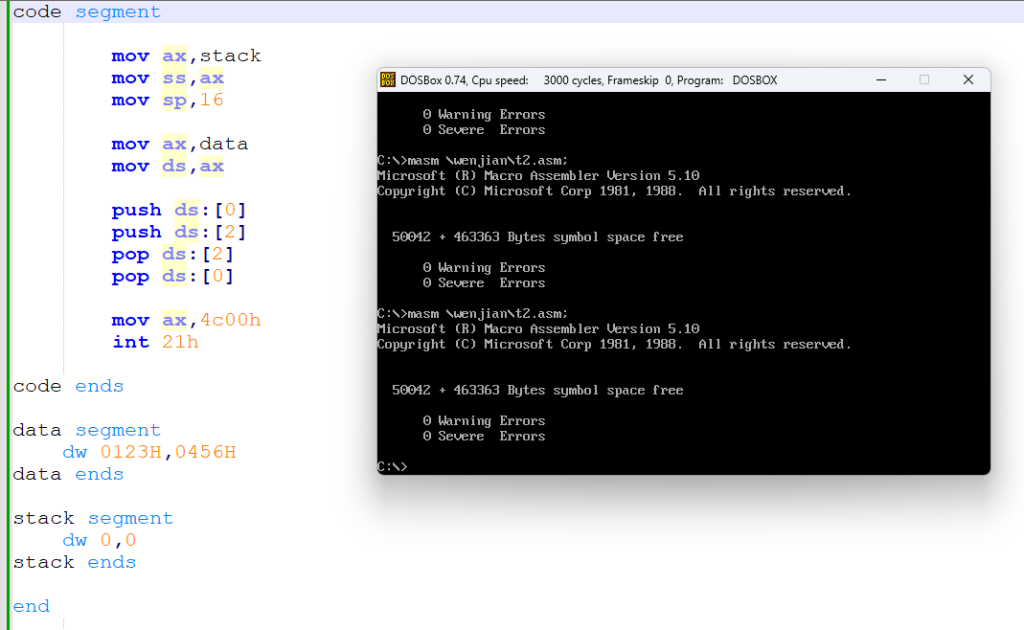
(这个图来解释一下上面的第一点)
4.然后的话,再说个情况,就是任何的 assume 其实都可以不用去写那些 ds:data,ss:stack,只用写一个 cs:code 就行,反正不写其他的不会报错,而不写这个 cs 在常规情况下就会报错,这个后面询问师傅和查阅相关资料,都表明这个 assume 不仅仅是简单的将段和寄存器联系,实现的就是定偏移,读写权限等等,比如 code 段就只能是 r-x,data 段是 r–,bss 是 rw-之类的,反正最好还是写上
上面那个是师傅和一些资料的解释,肯定是没有问题的,然后我自己又写了一段汇编代码,发现了几个新的问题,我也来对这个 assume 作用提一下自己的见解
先用简短的语言描述一下这个东西,然后再做验证
assume ds:段名1 mov ds,段2 mov ax,段1中的第二个变量。最终结果ax保存的是段2中的对应与段1中第二个变量相同地方的东西(注意是db,dw....)过程:编译器是在段1中查找变量名,并把变量转换为偏移地址,但访问时使用ds:偏移地址 这时ds保存的是段2的段地址,所以访问到的是第二个段对应偏移地址的内容
下面来验证一下
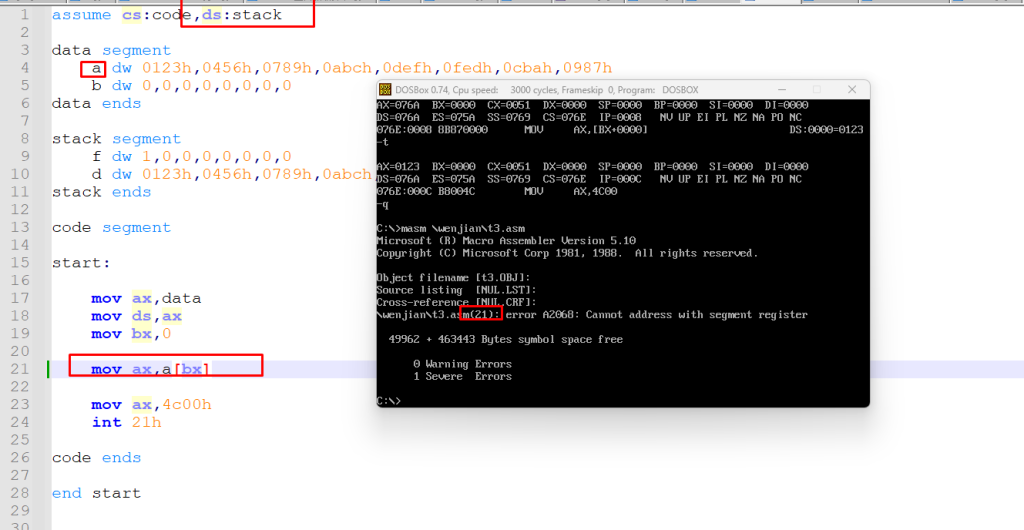
这里可以发现它竟然报错了,但明明在代码段里面写了,但却报错,然后把这个 a 改成 f 试一下
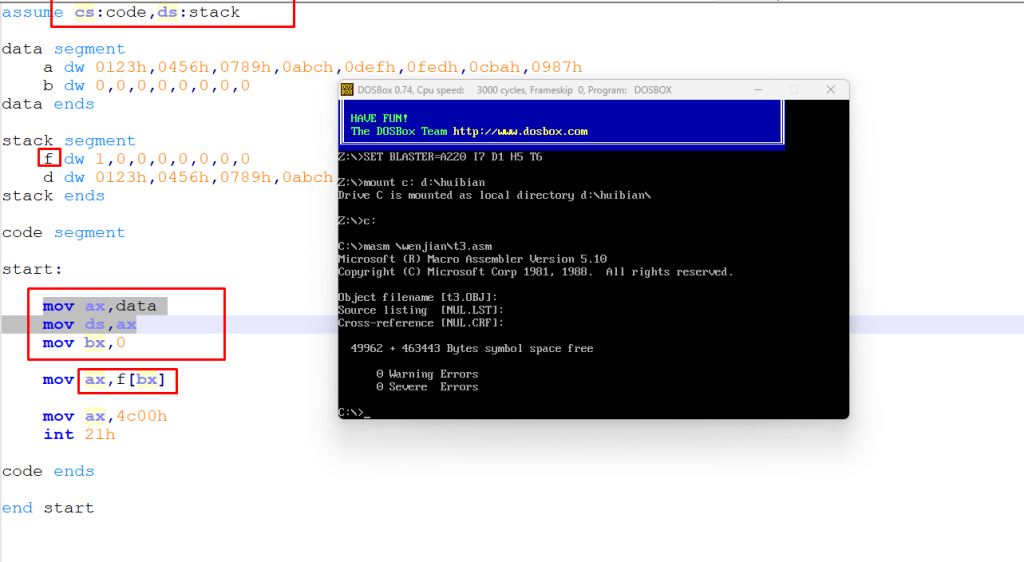
然后看一下运行结果,看看 ax 是 0 还是 123h
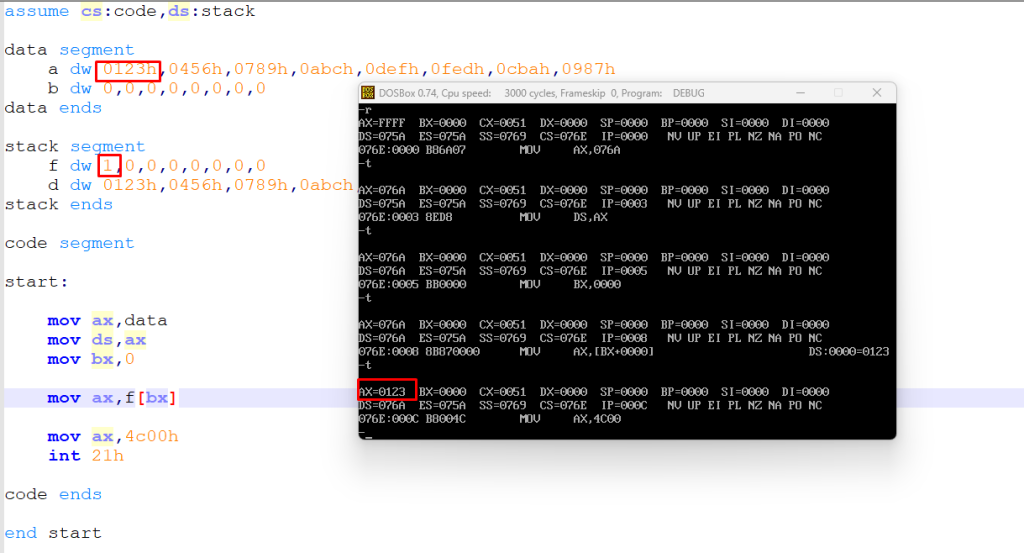
真的是非常神奇,通过这个例子就可以看出,assume 其实在代码段定义之前就已经默认了一个段地址,而且就算是后面在代码段里面改这个数据段的地址,那么也只能用之前在 assume 里面定义的变量名称,虽然之后 ax 用的确实是 123h,就像是我上面总结的那段话一样,不知道现在为啥说不清了,可能时间过去太久了,反正上面那段话就很清晰了!这里就是简单解释一下这个例子
5.最后,就是在翻阅英文版的汇编语言的时候,它说了这样的一段话
When the program loader leads an .exe program from disk into memory for execution,it constructs a 256-byte(100h)psp(program segment prefix)on a paragraph boundary in available internal memory and stores the porgram immediately following the boundary. the loader then
..initializes the address of the code segment in cs
..initializes the address of the stacd segment in ss and
..initializes the address of the psp in ds and es (我的注释:把psp的值赋给ds和es)
看到最后一句了吗,这就是说 assume cs:data,ds:data,ss:data 这句其实已经分别给cs,ds和ss段寄存
器相应赋值了,但是随后加载器又把psp的地址赋给了ds和es寄存器,而我们要的ds地址不是psp,这是在
代码执行之前完成的,所以我们要在代码中显示地指明MOV AX,DATA MOV DS,AX ,而不用指明cs,ds及
ss的寄存器
相信大家都看明白了,其实是已经有赋值的,只不过加载器又改为了 psp 的地址(这个名词不懂的话,去翻翻我写的关于王爽汇编的那篇笔记),这点和国内这一版的汇编语言还是有些出入的,大家理性看待就行
Okk,想说的都说完了,希望大家能有所收获吧,不用为这个问题困惑
- 结语
这些见解不一定全对,但也差不多,毕竟例子和事实都摆在这里,汇编语言真的很重要,大家一起继续加油鸭!!!